
𝐓𝐞𝐚𝐜𝐡𝐢𝐧𝐠 𝐆𝐞𝐧𝐀𝐈 𝐭𝐨 𝐭𝐡𝐢𝐧𝐤 𝐛𝐞𝐟𝐨𝐫𝐞 𝐬𝐩𝐞𝐚𝐤𝐢𝐧𝐠

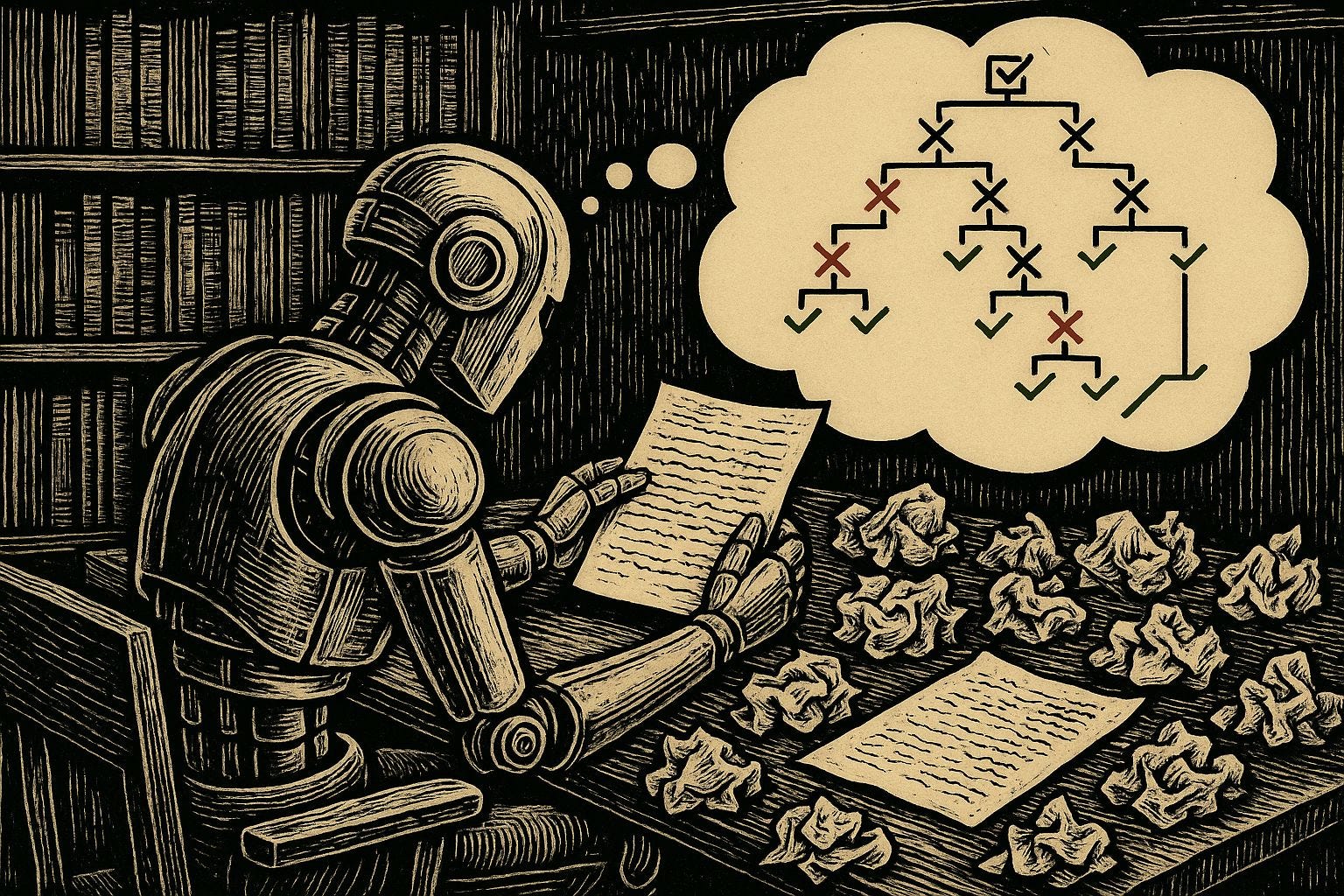
A recent interview with Eliezer Yudkowsky (known for his work on artificial intelligence safety and rationality) was in mind while reading this summer’s ICML proceedings, and I found STAIR worth sharing. Its key move is to 𝐭𝐫𝐞𝐚𝐭 𝐬𝐚𝐟𝐞𝐭𝐲 𝐚𝐬 𝐚 𝐬𝐞𝐚𝐫𝐜𝐡 𝐨𝐯𝐞𝐫 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐩𝐚𝐭𝐡𝐬 – the model “thinks before it speaks,” exploring multiple internal branches and selecting a response that is scored to be both safe and helpful.
This matters because 𝐆𝐞𝐧𝐀𝐈 𝐦𝐨𝐝𝐞𝐥𝐬 𝐜𝐚𝐧 𝐡𝐞𝐥𝐩 𝐛𝐚𝐝 𝐚𝐜𝐭𝐨𝐫𝐬 𝐝𝐨 𝐭𝐞𝐫𝐫𝐢𝐛𝐥𝐞 𝐭𝐡𝐢𝐧𝐠𝐬; this work is about keeping GenAI models (like Claude, Gemini, and ChatGPT) useful without just saying no to everything and without assisting harmful intent.
Technically speaking, STAIR adds 𝐬𝐚𝐟𝐞𝐭𝐲-𝐚𝐰𝐚𝐫𝐞 𝐜𝐡𝐚𝐢𝐧-𝐨𝐟-𝐭𝐡𝐨𝐮𝐠𝐡𝐭 𝐚𝐧𝐝 𝐮𝐬𝐞𝐬 𝐒𝐈-𝐌𝐂𝐓𝐒 (𝐒𝐚𝐟𝐞𝐭𝐲-𝐈𝐧𝐟𝐨𝐫𝐦𝐞𝐝 𝐌𝐨𝐧𝐭𝐞 𝐂𝐚𝐫𝐥𝐨 𝐓𝐫𝐞𝐞 𝐒𝐞𝐚𝐫𝐜𝐡) 𝐩𝐥𝐮𝐬 𝐚 𝐩𝐫𝐨𝐜𝐞𝐬𝐬 𝐫𝐞𝐰𝐚𝐫𝐝 𝐦𝐨𝐝𝐞𝐥 to guide test-time search toward answers that balance safety and helpfulness. That balance matters in, for example, healthcare, education, government, and finance, where the 𝐥𝐢𝐧𝐞𝐬 𝐛𝐞𝐭𝐰𝐞𝐞𝐧 𝐥𝐞𝐠𝐢𝐭𝐢𝐦𝐚𝐭𝐞 𝐚𝐧𝐝 𝐫𝐢𝐬𝐤𝐲 𝐪𝐮𝐞𝐬𝐭𝐢𝐨𝐧𝐬 𝐚𝐫𝐞 𝐨𝐟𝐭𝐞𝐧 𝐛𝐥𝐮𝐫𝐫𝐞𝐝. Big labs like Anthropic and OpenAI have pushed RLHF, Constitutional AI, and strong evaluations; STAIR complements that direction by making the 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠 𝐩𝐫𝐨𝐜𝐞𝐬𝐬 𝐢𝐭𝐬𝐞𝐥𝐟 𝐬𝐚𝐟𝐞𝐭𝐲-𝐚𝐰𝐚𝐫𝐞 𝐚𝐧𝐝 𝐛𝐲 𝐬𝐞𝐥𝐞𝐜𝐭𝐢𝐧𝐠 𝐫𝐞𝐬𝐩𝐨𝐧𝐬𝐞𝐬 𝐭𝐡𝐚𝐭 𝐫𝐞𝐝𝐮𝐜𝐞 𝐮𝐧𝐬𝐚𝐟𝐞 𝐨𝐮𝐭𝐩𝐮𝐭𝐬 𝐰𝐡𝐢𝐥𝐞 𝐩𝐫𝐞𝐬𝐞𝐫𝐯𝐢𝐧𝐠 𝐡𝐞𝐥𝐩𝐟𝐮𝐥𝐧𝐞𝐬𝐬. I am always eager for more tools that help navigate the tricky balance of alignment!
A link to the original ICML contribution can be found here (Authors: Yichi Zhang · Siyuan Zhang · Yao Huang · Zeyu Xia · Zhengwei Fang · Xiao Yang · Ranjie D. · Dong Yan · Yinpeng Dong · Jun ZHU)